1 Dyson Robotics Lab, Imperial College London 2 The University of Hong Kong
We introduce EscherNet, a multi-view conditioned diffusion model for generative view synthesis. EscherNet offers exceptional generality, flexibility, and scalability within its design — it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, conditioned on any number of reference views with any camera poses.
Just drop a few images with poses (estimated by Dust3R or any SLAM), EscherNet can generate any number of novel views in 6DoF.
Method Overview
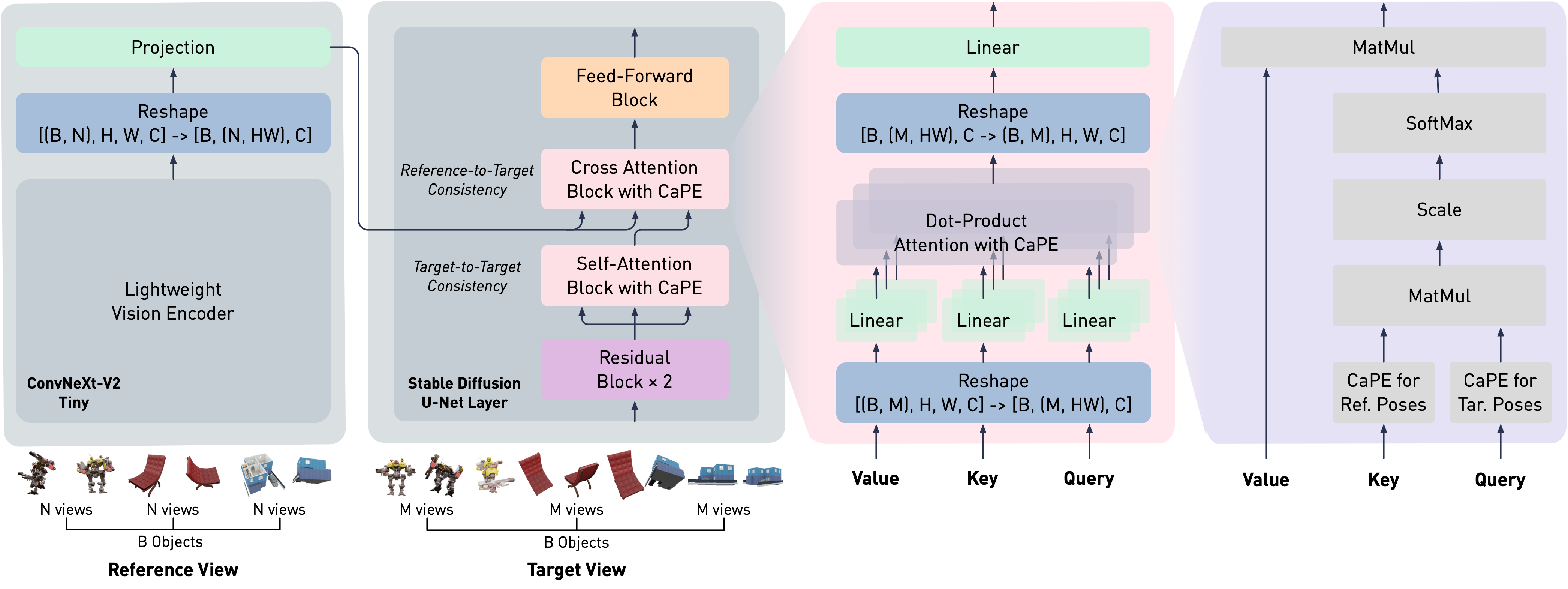
EscherNet is a multi-view diffusion model that takes N images + camera pose, and M queried camera pose as input and outputs M novel view images.
We design EscherNet following two key principles: 1. It builds upon an existing 2D diffusion model, inheriting its strong web-scale prior through large-scale training, and 2. It encodes camera poses for each view/image, similar to how language models encode token positions for each token. So our model can naturally handle an arbitrary number of views for any-to-any view synthesis.
EscherNet adopts the Stable Diffusion architectural design with minimal but important modifications. The lightweight vision encoder captures both high-level and low-level signals from N reference views. In U-Net, we apply self-attention within M target views to ensure target-to-target consistency, and cross-attention within M target and N reference views (encoded by the image encoder) to ensure reference-to-target consistency. In each attention block, CaPE is employed for the key and query, allowing the attention map to learn with relative camera poses, independent of specific coordinate systems.
Camera Positional Encoding (CaPE)
The key design component of EscherNet is Camera Positional Encoding (CaPE), to encode camera poses efficiently and accurately within a transformer architecture for image tokens.
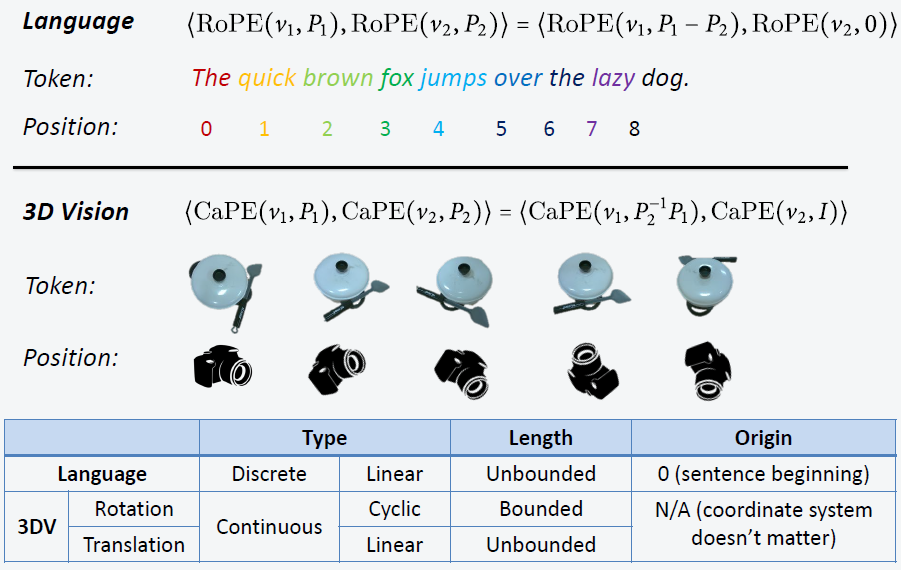
Inspired by Language domain, each word is a token and the position is encoded via Positional Encoding, e.g. rotary positional embedding (RoPE).
We treat each 2D image view as a token and the camera pose as token position encoded by CaPE. Then Novel View Synthesis turns to image-to-image sequence prediction problem, conditioning on the input posed images, predicting the novel views at the queried 3D poses.
This enables EscherNet trained on 3-to-3 views, but can generalise to 100-to-100 views.
The analysis and comparison of designing a position encoding in 3D Computer Vision and Language domain.
Applications
Zero-shot Novel View Synthesis
We show EscherNet as a generative novel view synthesis method, that can synthesise novel views with large-scale priors.
Compared to 3D diffusion models (e.g., Zero-1-to-3), EscherNet is more flexible in view numbers and 3D consistency.
Compared to scene-specific neural rendering methods (e.g., NeRFs), EscherNet is zero-shot and scene-agnostic.
EscherNet is also able to apply on real world object-centric captures.
Compared to 3D Diffusion Models
We show that EscherNet significantly outperforms Zero-1-to-3-XL, despite it being trained on x10 times more training data. Notably, many other 3D diffusion models can only predict fixed target views or only conditioned on a single reference view, while EscherNet can generate multiple consistent target views jointly by taking flexible reference views.
Zero-1-to-3-XL
EscherNet (1 View)
EscherNet (2 Views)
EscherNet (3 Views)
EscherNet (5 Views)
EscherNet (10 Views)
GSO-30 Dataset /
Speed: ×1.00
Compared to Neural Rendering Methods
Compared to scene-specific neural rendering methods e.g., InstantNGP and 3D Gaussian Splatting, EscherNet offers plausible view synthesis on out-of-distribution scenes in a zero-shot manner, showing superior rendering quality with few reference views. Though EscherNet gains improvement with an increase in the number of reference views, it starts to lag behind the neural rendering methods.
Instant-NGP
3D Gaussian Splatting
EscherNet
NeRF Synthetic Dataset /
conditioned on
Speed: ×1.00
Results on Real-World Objects
EscherNet can generate plausible novel views on real-world objects, conditioned on 5 reference views captured by a single camera mounted on a robot arm.
5 Input Reference Views
EscherNet
Real-World Recording /
Speed: ×1.00
Single/Multi-Image 3D Reconstruction
EscherNet's ability to generate dense and consistent novel views significantly improves the reconstruction of complete and well-constrained 3D geometry using NeuS.
PointE
ShapeE
One2345-XL
DreamGaussian-XL
SyncDreamer
Ground-Truth
EscherNet (1 View)
EscherNet (2 Views)
EscherNet (3 Views)
EscherNet (5 Views)
EscherNet (10 Views)
NeuS (10 Views)
GSO-30 Dataset /
Text-to-3D Generation
Text-to-3D generation is achieved by conditioning EscherNet's input views on the output of off-the-shelf text-to-image generative models, e.g., MVDream and SDXL.
SDXL Prediction
EscherNet
MVDream Prediction
EscherNet
Text-to-Image Model /Input Text Prompt /
Speed: ×1.00
BibTex
@inproceedings{kong2024eschernet,
title={Eschernet: A generative model for scalable view synthesis},
author={Kong, Xin and Liu, Shikun and Lyu, Xiaoyang and Taher, Marwan and Qi, Xiaojuan and Davison, Andrew J},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9503--9513},
year={2024}
}
Miscs
The initial stages of this project yielded some incorrect outcomes; however, we find the emerging patterns aesthetically pleasing and worthy of sharing.