CausNVS enables autoregressive view synthesis. In contrast, prior non-causal NVS models, when sampled autoregressively at test time, drift quickly due to error accumulation.
TL; DR: CausNVS is an autoregressive diffusion model for next novel view synthesis with relative pose encoded attention (CaPE) and efficient KV cache inference, towards real-time world modelling, AR streaming and interactive online generation.
Method
We design CausNVS to: (1) synthesize the next view in a streaming manner, (2) train effectively on arbitrary input-output configurations, and (3) roll out efficiently with KV cache, without being bound to any global coordinate frame.
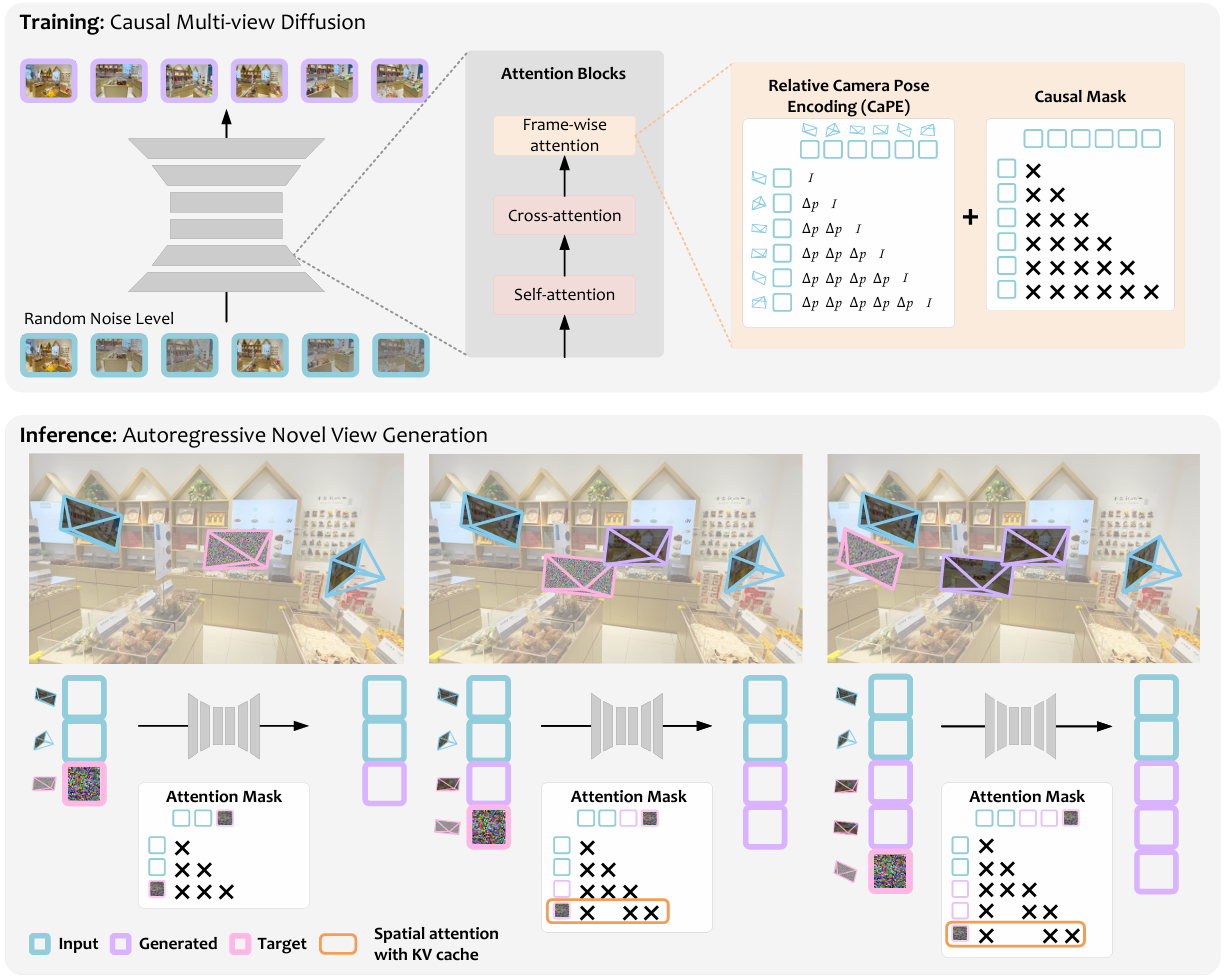
Causal Multi-view Diffusion Pipeline
Each view is tokenized with its camera pose and noise level, and processed with frame-wise
self-attention, causal masking, and CaPE. At inference time, given a variable number of conditioning views, the model performs autoregressive denoising
using KV caching with spatial attention window, enabling efficient and scalable 3D view synthesis.
CaPE: Relative Camera Pose Encoding
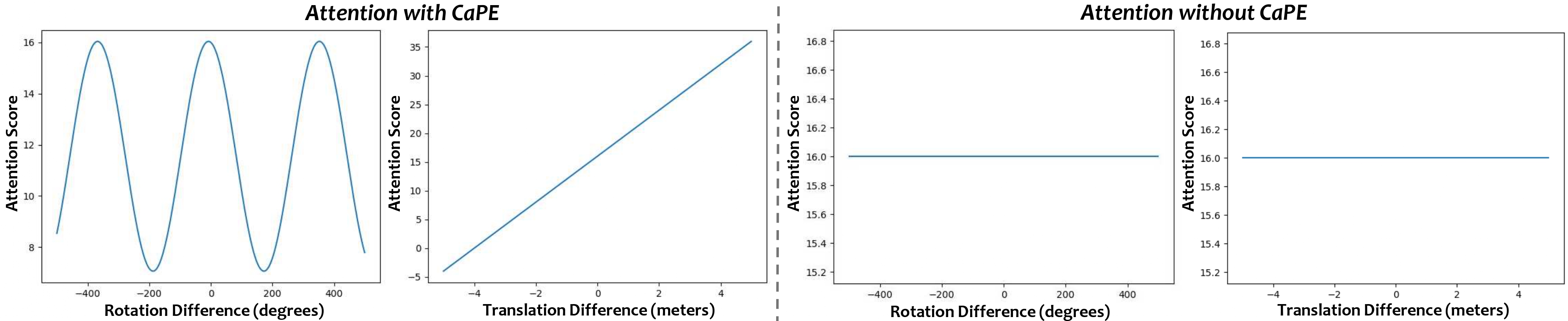
We analyze how attention responds to relative pose changes by initializing queries and keys randomly, and varying rotation or translation separately. With CaPE, attention scores change periodically with rotation and linearly with translation, indicating an SE(3)-aware inductive bias. Without CaPE, attention remains invariant to pose changes.
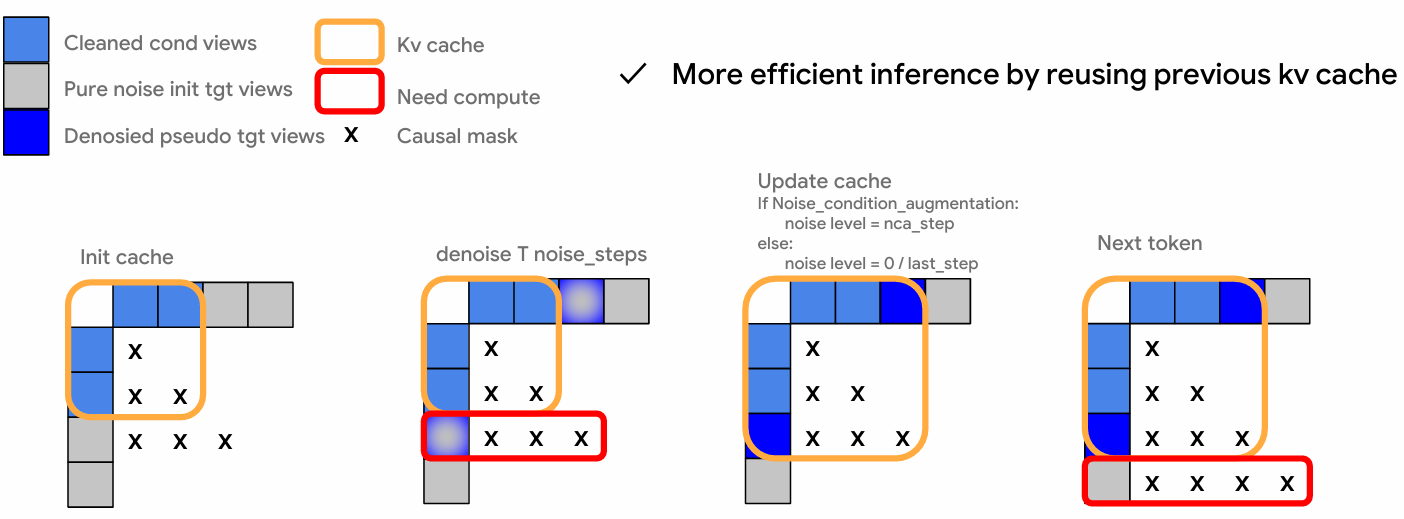
KV Cache with Causal Diffusion
CausNVS caches only (1) the final denoised latents (or latents with small noise when using noise augmentation), and (2) frame-wise attention key-value pairs for cross-view communication.
Results
All results from CausNVS are generated in an autoregressive manner, where each novel view is conditioned only on the input and the previously generated views. This setup naturally supports streaming and interactive generation scenarios, where future camera poses may not be known in advance.
This differs from existing multi-view models (e.g., 4DiM, SEVA, MotionCtrl), which are typically designed for fixed-length trajectories and require the entire camera path to be specified before inference. Such methods commonly rely on parallel decoding and may be less suited for incremental or online generation settings.
Customized Pose Trajectories
CausNVS generalizes to novel trajectories under diverse camera motion patterns, including forward, backward, circular panning, and rotation. The generated views remain 3D-consistent with previously synthesized ones upon revisiting the initial camera pose. The following examples show results for generating F = 8 views from a single input view (N = 1).
Input
Move Forward
Move Backward
Rotate 90
Rotate 90 and Back
Scene /
Speed: ×1.00
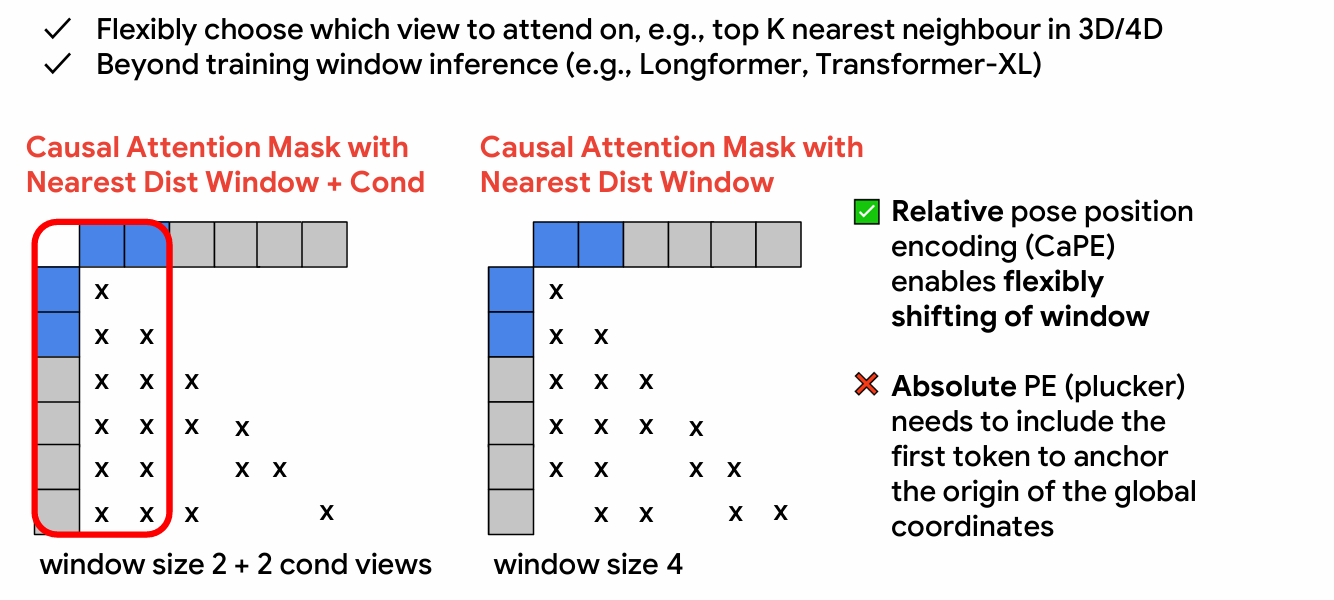
KV Cache with Attention Window
CausNVS supports flexible attention window setup. With window size 1, attention is limited to input views, leading to inconsistency across generated frames. Window size 4 already achieves comparable results to full attention. Users can save computational resources by adjusting the attention window size.
Input
GT
Full Window
Window 16
Window 4
Window 1
Speed: ×1.00
N-to-M Autoregressive Novel View Synthesis
With the causal mask, CausNVS is efficiently trained with variable input-output view configurations jointly in a single pass, allowing it to generate any number of novel views (M) from a variable number of input views (N). The total number of views F = N + M.
CausNVS Improves with More Input Views
We observe that providing more input views leads to improved results that are more 3D-consistent and semantically faithful to observations with finer control over camera pose.
DL3DV /
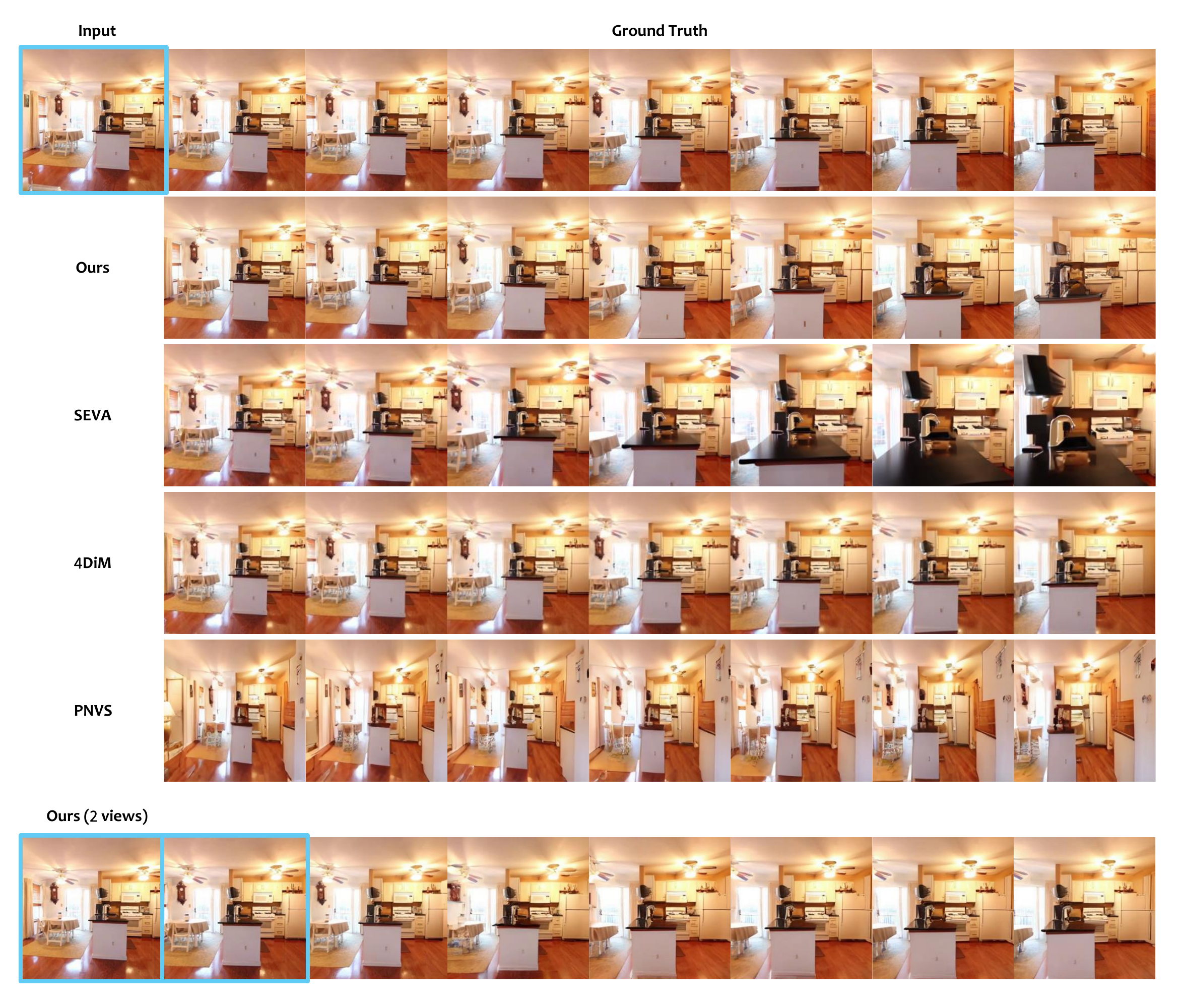
Comparisons with Baselines
CausNVS achieves superior pose control and scene consistency compared to strong baselines.
RealEstate10K /
BibTeX
@inproceedings{kong2025causnvs,
title={CausNVS: Autoregressive Multi-view Diffusion for Flexible 3D Novel View Synthesis},
author={Kong, Xin and Watson, Daniel and Strümpler, Yannick and Niemeyer, Michael and Tombari Federico},
booktitle=,
pages=,
year={2025}
}